Introduction
In many cases, it appears that there are dependent tickets in a sprint within a team or even across several scrum teams. In a perfect world those dependencies would be avoided, but unfortunately, in real-world the business needs prevail and to shorten the release cycle dependencies are introduced. This is a technical article that focuses on a way to manage dependent tasks in software development teams.

The old-fashioned way
The straight-forward approach would be to start working on a task as soon as the dependent task is merged into the mainstream branch. With such an approach though, some team members will idle or wait until a task is ready to be picked up. At some point, there will be little to no time to implement the remaining dependent tasks. Finally, the last tasks are doomed, carried over to the next sprint and the team is unhappy.
Why does this happen even though the capacity of the team is correctly estimated? Mostly because of the idle time when waiting for a team member to complete a task. There are often delays and even though they might be small in time have an exponential impact especially on short sprints.
Working on dependent tasks simultaneously
Yes, there is a way to do that with a small overhead. When team members work on tasks simultaneously, there are several advantages.
Better collaboration
When team members work simultaneously on dependent tasks, this is a kind of pair programming model. One team member needs to be aware of its dependency and another team member needs to be aware of its dependant. The team has now wider knowledge of the problems being solved during the current sprint.
Avoiding the idle time
When tasks are approached concurrently, there is no need to wait until something is fixed (or made available). All team members can work on the dependant tasks simultaneously with higher than usual ad-hoc discussions due to the questions that arise from time to time.
Pull requests ready for code review earlier
When a team member is using a branch from which his/her branch originates from, it is always easier to approve the origin pull request. This is mostly because of the awareness of the implementation of the dependent ticket. The origin is well tested and reviewed already during the implementation process. The pull request of origin is a no longer unknown territory.
Using chained (stacked) pull requests
To accomplish this level of concurrency within the team, the proper tooling is needed. With GIT-based versioning systems, this is straight-forward to implement. The following steps define the process in more detail.
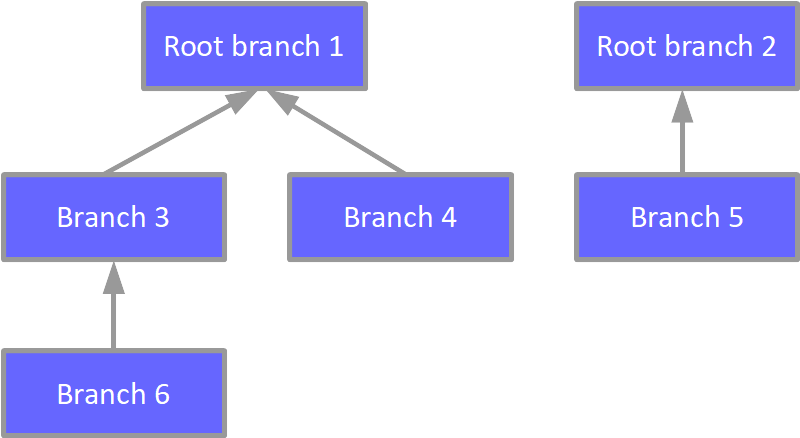
Outline the dependencies clearly
During the planning session for the current sprint, the dependency chain between the tasks has to be defined. The chain of pull requests will follow exactly this same definition. Changing the chain in the mid-development process is not desired due to the huge rebasing overhead.
Start with the root tasks first
In every dependency chain, there are always tasks that are not dependent on any other task. Those are the root tasks of the chain. Work on those tasks can immediately be started from day one.
Do core implementation first
This might contradict with the test-driven development where tests are implemented first. To reduce the complexity of managing the dependency chain of pull requests though, it is easier to work on core implementation first. This way the team members that are dependent on a particular functionality will have access to it sooner.
Organize and code review in a FIFO queue
The first branch created must be code-reviewed first and merged into the mainstream first. After each merge, the continuous integration will trigger and if there are issues like breaking the mainstream build they will be fixed on time while the problem is still small.
The overhead
Although there are many benefits in maintaining a chain of dependent branches in the versioning system, there are also some small deficiencies.
Rebasing or merging
The chain of pull requests need to be kept in sync and this costs effort. The modern tools though provide easy one-click synchronization with the origin branch when there are no conflicts. This can be used for on-demand synchronization when it is safe to pull in the changes from the origin. When the build is green and the functionality is usable, it is time to sync.
Teamwork
Maintaining the dependency chain requires a collaborative team and each team member should be ready and eager to collaborate with the other team members. Working on a chain cannot be productive when people are isolated and don’t talk with each other.
Conclusion
It is always preferable to push back dependent tickets out of the current sprint. When for business needs though, such tasks need to be implemented simultaneously, maintaining a chain of derived branches is a very convenient and successful approach to handle the dependency overhead between different tasks.
The tooling
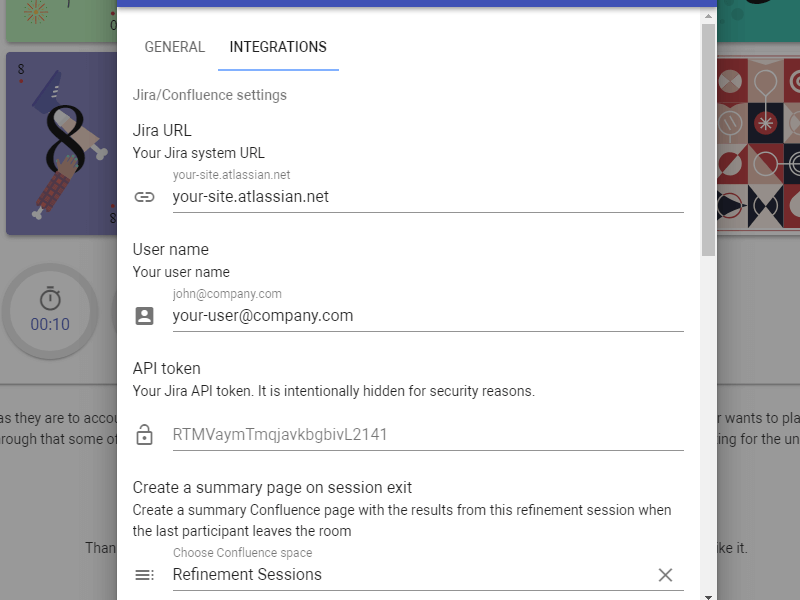
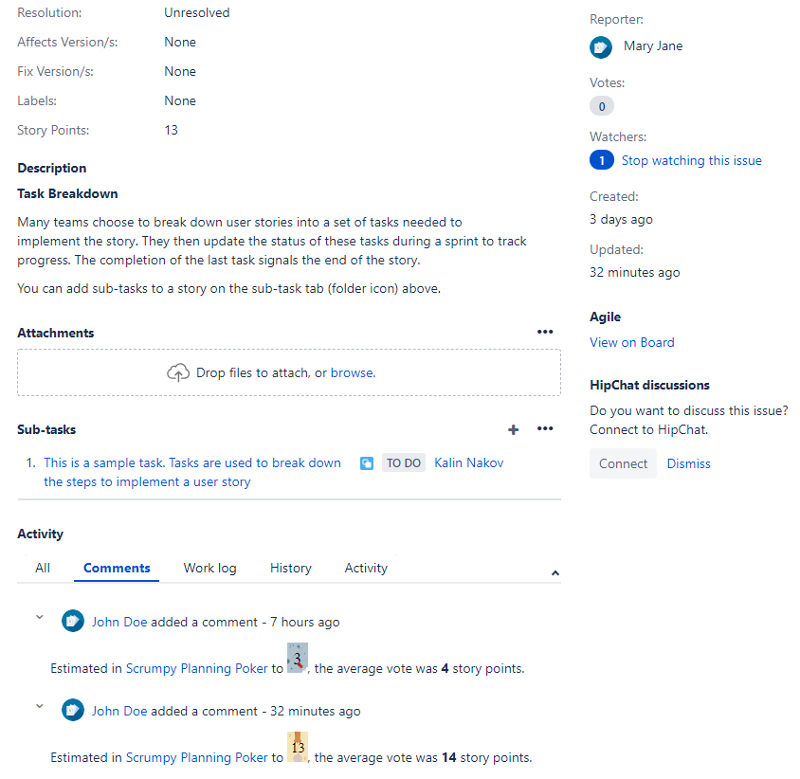
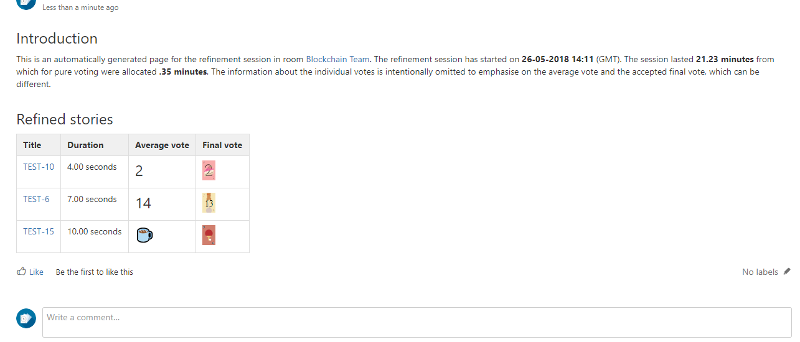
Scrumpy Planning Poker is a great tool for estimating stories correctly. The stories estimated properly will help the team clearly define its capacity and have a successful sprint. When tickets are estimated, dependent tickets are revealed through discussion and marked as such in the ticketing system. You can start your first Scrumpy Planning Poker session right away!
Try NOW!Tutorial
The following video shows how to use the Scrumpy Planning Poker application by becoming a moderator and creating a refinement session. Scrumpy Planning Poker saves you time and keeps your team engaged!