Introduction
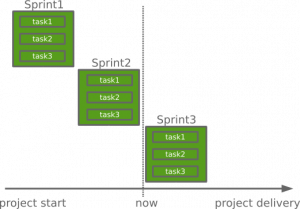
The predictable velocity is the ability to always know the volume of work that will be implemented by a team for a given time based on team’s availability.
The problem of varying velocity
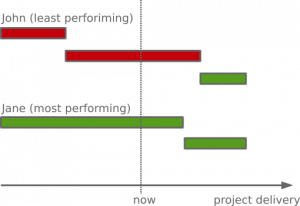
When velocity varies between sprints, planning the release of a project becomes a tough process. It is never known when the tasks will be delivered and so the whole scrum process is broken. The sense of chaos is everywhere and that doesn’t help in improving team’s motivation.
Usually, the varying velocity is caused by the fact that individual team members try to deliver the best they can and they promise more than they can fulfill. Unfortunately, in a collaborative environment with a development process that is well set up, there is a bit more than just the straight-forward implementation of a task. Some team members get lucky and land on tasks that can be implemented relatively simple, but others hit a problem nobody has thought of in advance. In the end, during one sprint the team has a higher velocity (due to finalizing carry-overs), while during another sprint the team has a lower velocity (and cause carry-overs).
Having carry-overs causes the feeling that the job is not well done, the team can do more, but always something happens, something unpredictable. The management raises feels the problem, sees the failing deadlines and this creates a tension among team members.
The common problems in maintaining predictability
The problems depend on the project specifics, but many of them are common to all types of projects and will be addressed here with appropriate solutions.
Expect the unexpected
There are some tasks that require research prior to starting. Imagine, for example, some feature that requires interaction with a third party company that may not immediately respond when it is needed. Or this can be a feature that actually cannot be implemented in a straight-forward way due to a wrong understanding of the underlying technology when creating the task.
If such a task is added in a sprint without the needed research in advance, there is a high risk that it takes more time than expected and it will be considered “underestimated”. Some may argue that there is a need for a spike in advance to do a research on the subject. But how to know for which task a research spike is needed?
The only way is to start working on a task in advance. When the work on a task starts before it is actually planned makes it possible to find all issues before they actually occur. With such an approach, the task will be placed in a sprint only when it is absolutely clear and some amount of the work on it is already done.

Avoid fuzzy task definitions
Some tasks are defined in a way that they look ok-ish to their creator but do not include important details in their description. There are some implementation specifics that may seriously affect the task fulfillment.
Business people may argue that there must be no technical details in the task definition, but on the contrary, technical implementors find the business requirements too fuzzy to work on.
The solution is to have technical design documents in which the implementation task is referenced. Then it is clear from the technical point of view what exactly needs to be implemented.
It is also good to place technical details in the tasks’ description so that implementors know what needs to be done and some details can ring a bell for possible issues.
Decrease your capacity in a Fibonacci row
Sometimes team members go on vacation or there are holidays during the sprint for all team members. Training and other internal company events also contribute to lowering the team’s availability (the volume of work on project tasks). In this case, the capacity has to be lowered according to the missing people.
The velocity is considered constant, but it is calculated based on the average velocity of all people in the team. For simplicity, let’s look at the case when one person does one story point per day. If one person is missing for one day, the sprint’s capacity has to be lowered with 1 story point. If 2 people are missing for 2 days (2×2=4 story points), the capacity should be lowered with 5 story points instead. Finally, if 2 people are missing for 3 days, the capacity should be lowered with 8 points instead of 6 to include the dependencies risk.

Avoid dependent tasks
In many cases, one task is done by one person and it is a dependency of another task done by another team member. This causes in-team or inter-team dependencies. When the first task is not implemented on time, all dependent tasks are pushed back. This causes team members to idle and then rush when dependencies are done and this way misusing the precious time at work.
Dependent tasks can be started earlier so that when the next sprint starts the first critical tasks on which the others depend will be almost completed. This will reduce the dependency impact on the team’s velocity for the current sprint.
Estimate honestly
Giving honest estimates to tasks is a tricky task and it involves the attention of the whole team. Everyone should be careful and give estimates without being affected by other team members estimates. Only honest estimates can properly show how much time it will take for an epic to be completed and the release dates matched.
The tooling
Scrumpy Planning Poker is a great tool to keep team members attention during the refinement sessions and make fun out of voting. It works on all platforms inside the web browser and can be used to define the story points for implementation tasks. You can start your first Scrumpy Planning Poker session right away!
Try NOW!Tutorial
The next video shows how easy it is to vote for a task and estimate it with Scrumpy Planning Poker.