Introduction
Most of the time estimating with story points is neglected and performed in chat rooms where all messages are visible, or verbally when everything is audible. Knowing how other people voted for a story estimation twists the outcome of voting and the result is not correct. An incorrect estimate repeated for several stories leads to wrong business plans and delayed or canceled deliveries. Let’s investigate what happens in an open vote.
The characters in voting
There are several characters participating in an open estimation vote. Depending on who goes first, the story gets estimated differently, but mostly far from the honest estimate. Why does the open vote make it that significant who goes first? Because of the sheep effect, other team members tend to copy the original estimate.

The “I know it all” team member
Every team has at least one member who thinks he/she has the most knowledge of the system. Usually, this is the first vote since things are known. There are often overseen details though that can spoil the expectations. Those details can be discovered in advance, but only if a discussion is provoked. This cannot happen in an open vote.
The “I know it all” team member usually votes with a lower estimate than the honest estimate. Probably only this team member can execute the estimated story for that little time and only when he/she gets lucky.

The rest of the team members vote the same so at the end, it appears that the estimated task is easy and anyone can do it for the appointed time. Unfortunately, often this task is picked by other team members.
The “Introvert” team members
Usually, those team members are more than one and they are afraid to be the first voters. They expect someone else to vote first so they can repeat the vote. They rarely participate in any conversation for a particular issue of a story and reply only when being asked. The introverts vote second, just before the “I don’t care” team members.

The “I don’t care” team members
During implementing stories it is difficult to catch those team members, but during the vote, it is most obvious. They always vote last and repeat the estimates of the others. If the estimates are different, they announce the one that repeats most. The reason is that they don’t want to be asked questions why a lower or a higher estimate was announced. They never collaborate during the refinement session and desperately try to avoid any questions being asked.

The Tired employee
Some of the team members just can’t stay focused for a long time and so they miss some important part of the discussion. For various reasons they lose context in the conversation and tend to give random story points to tasks or desperately try to find out what is the most repeating vote so they can copy it.

How to keep the attention during estimation
Estimation is important since only the honestly assigned story points can bring a project flawlessly to the release date. The most important part of the honest estimation is to never allow team members to leverage the sheep effect by using special estimation tools like paper cards or software.
The team members should never see each other’s estimates until they are revealed by the moderator. This way Introvert starts thinking, Mr. “I don’t care” gets interested and Mr. “Sleepy Tired” wakes up. The best question to ask, especially when deviating from the average voter is “why did you vote X story points”. This will provoke some conversation, some discussion with the moderator on the real implementation issues for the story. The close-ended questions like “would you agree” with X story points automatically lead to the useless answer “yes”.
With an estimation tool that brings some joy to the boring refinement session and requires each team member to stay awake and ready to discuss, it is no longer difficult to give proper estimations even to complex stories.
The tooling
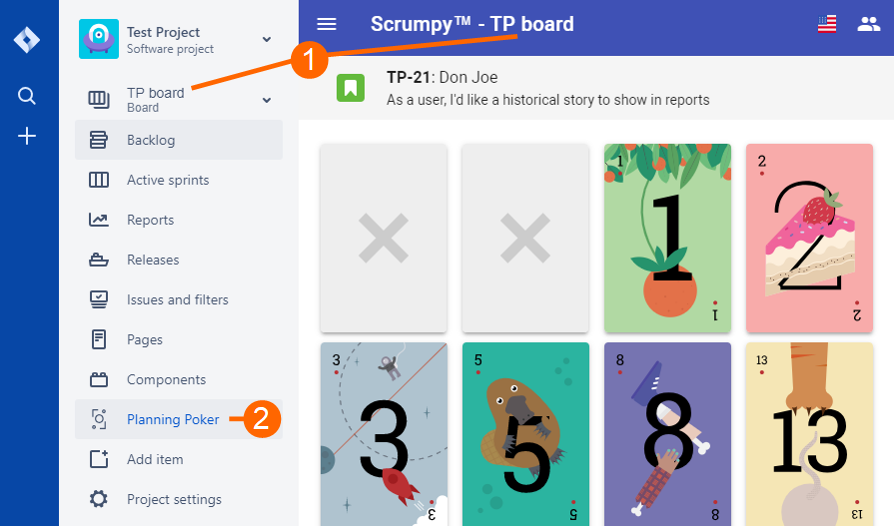
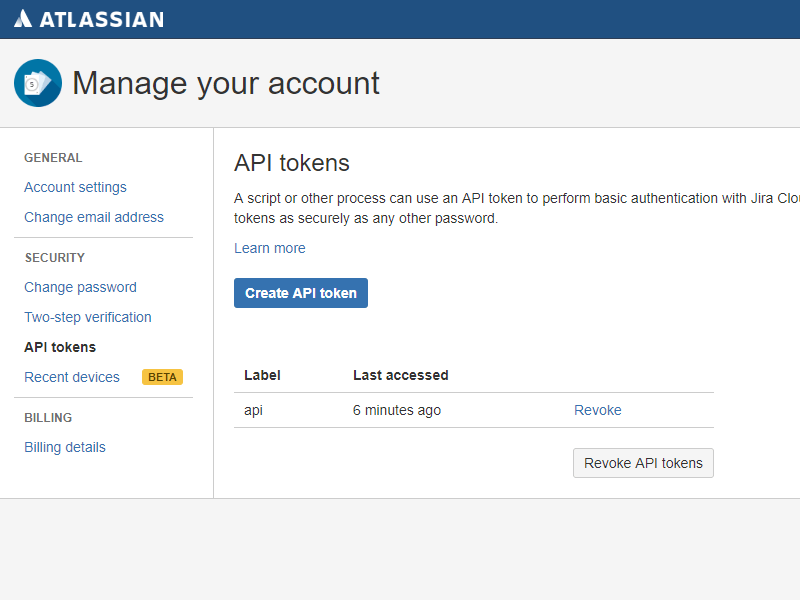
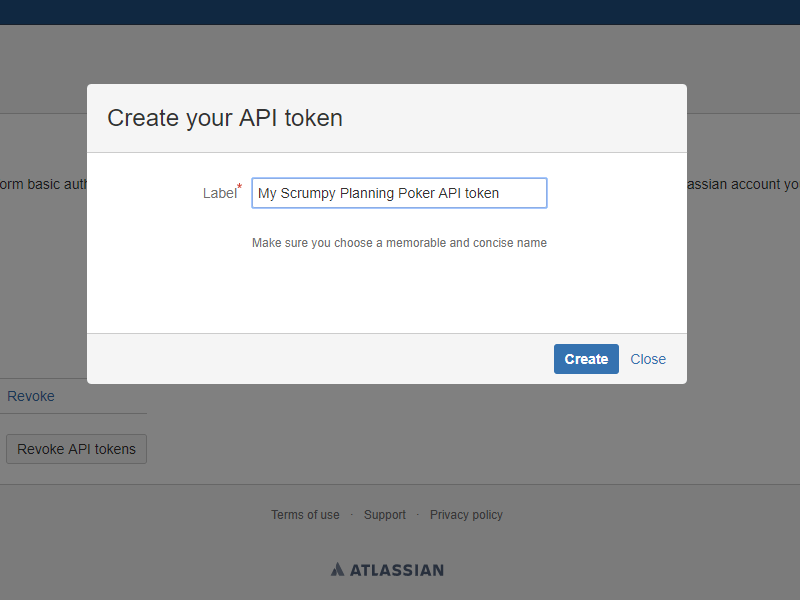
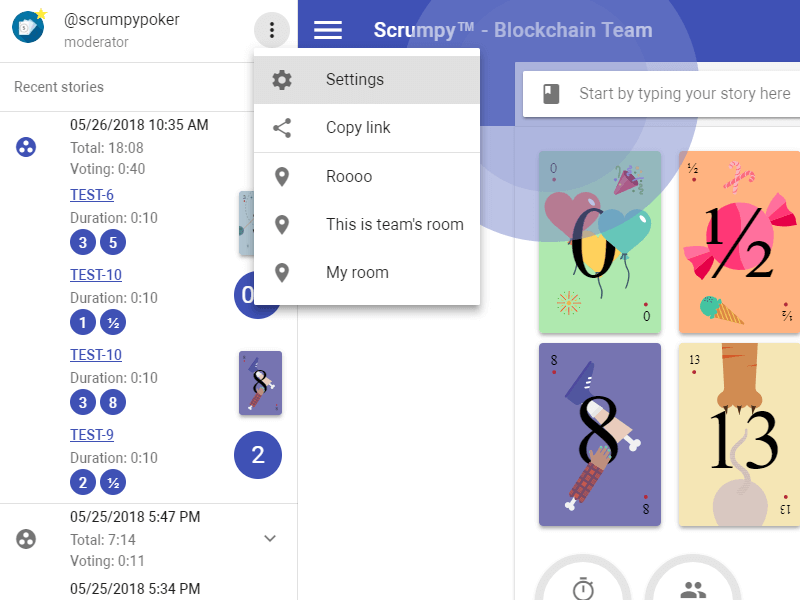
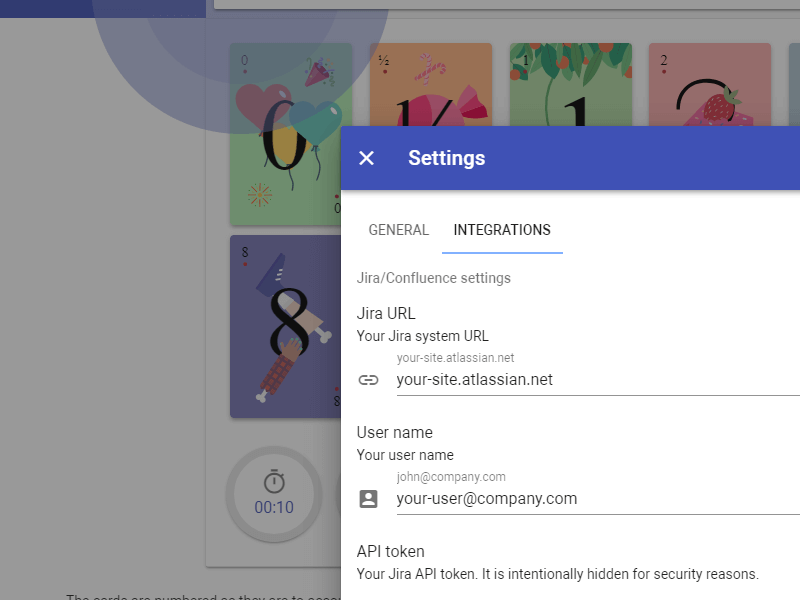
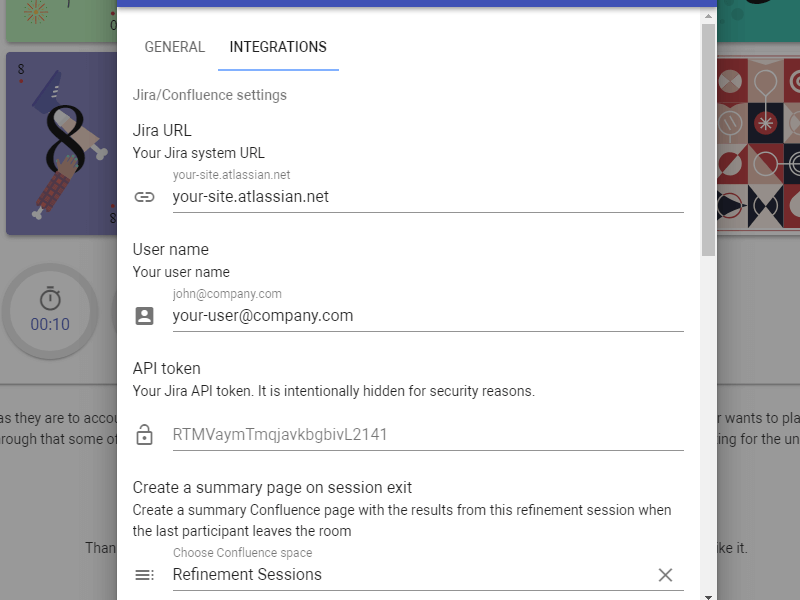
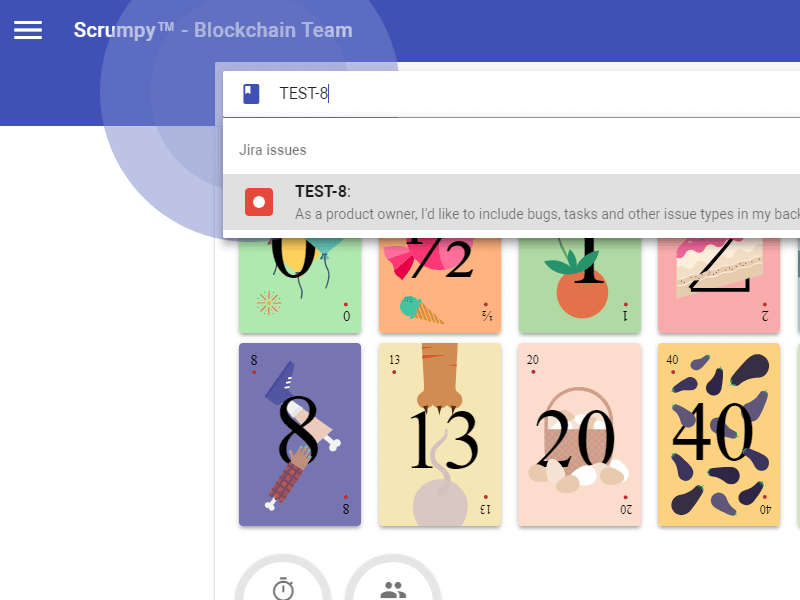
Scrumpy Planning Poker is a great tool to keep team members attention during the refinement sessions and properly estimate stories in Jira (and not only). It helps team member stay awake, have fun and estimate honestly even the most complex stories. You can start your first Scrumpy Planning Poker session right away!
Try NOW!Tutorial
The following video shows how quick and easy it is to start a refinement session, personalize the theme and language and estimate stories honestly. Scrumpy Planning Poker is fun and engaging!